Bitcoinのmempoolについて、既存の課題とそれを改善する新しい設計案が提案されている↓(最近Optechで始まった限定シリーズも、この辺りの話があるから?)
現在のmempoolの課題
mempoolには、Bitcoinネットワークでブロードキャストされた、まだブロックに格納されていない未承認のトランザクションが保持されている。この未承認トランザクションのすべてについて、インプットで参照する親トランザクションが承認済みのものであれば、トランザクション単体の手数料率を計算してソートするだけで簡単に優先順位が決められる。
ただ、実際は未承認の親を含む子トランザクションがあったり(CPFPとかで)、さらに孫が存在していたりと、関連トランザクションによる未承認のトランザクションチェーンが構成される。
現在のmempoolでは、プール内のこれらのトランザクションについて、祖先ソートと子孫ソートという2つのソート順を維持するようになっている。つまり、親子関係のあるトランザクションチェーンが形成される中で、あるトランザクションから子を辿っていくソートと、親を辿っていくソートが保持されている。この2つのソートを使用するアルゴリズムの問題点として次のようなものが挙げられている↓
mempoolからの退去
最近発生してるように、mempoolが混雑しmempoolのサイズを超えてトランザクションが溢れると、手数料率の低いトランザクションからmempoolから退去させられる。
この退去のアルゴリズムは、子孫手数料率が最も低いトランザクションをその子孫と一緒に削除するというもの。ただ、このアルゴリズムには問題があって、退去させたトランザクションが必ずしもマイニング時のトランザクション選択アルゴリズムにおいて最後の候補(最も収益性の低いもの)であるとは限らないこと。
たとえば、以下のようなトランザクションチェーンがある場合↓
graph TD;
A[Tx A: size 250, fee 250]-->B;
A-->C;
A-->E[Tx E: size 250, fee 49750];
B[Tx B: size 50000, fee 50000]-->D[Tx D: size 500, fee 52000];
C[Tx C: size 50000, fee 50000]-->D;
ここで、
- Tx Eから見た祖先の手数料率は、Tx size = 250 + 250 = 500、fee = 250 + 49750 = 50000から、100 sat/byte
- Tx Aから見た子孫の手数料率は、AからEすべてを加味するため、Tx size = 101000、fee = 202000から、2 sat/byte
この中では、Tx Aの子孫手数料率が一番低いけど、Eの祖先手数料率は一番高いという状況になる。
現状の退去アルゴリズムでは、子孫の手数料率をみて判断するので、Tx Aが退去対象に選ばれるが(その子孫も)、マイナーにとっては(A, E)のセットをマイニングするのが一番収益が高くなるという状況が発生する。
ここでの問題は、マイニングアルゴリズムにおける一番手数料収益があげられるトランザクションのセットと、退去のアルゴリズムにおける一番手数料率が低いトランザクションのセットのギャップにある。
現在のマイニングアルゴリズムの方も、祖先の手数料率を見ていくアルゴリズムで、性能と収益のバランスを取るもので、最も最適(収益性の高い)トランザクションのセットが見つけられるというものではない(CPFPのようなシナリオで最適なブロックを見つけられるかというと難しい)。
インセンティブ非互換のRBF
RBFにも課題がある。RBFを利用してトランザクションを置換する場合、新しいトランザクションに置換対象よりも高い手数料率を要求するというルールがある。ただ、この比較は新しいトランザクションと置換対象のトランザクションの手数料率を比較しているだけで、両者の子孫トランザクションは考慮されていない。そのため、手数料率の高い子孫トランザクションをmempoolから退去してしまう可能性があり、マイナーのインセンティブとは異なる置換が起きることになる。
また、BIP-125のオプトインRBFの場合、置換する新しいトランザクションのインプットに未承認のTxが含まれてはならないというルールがあるが、新しい未承認の親Txを含めることで結果的に親子で見た時の手数料率が上がる可能性もあり、これもマイナーのインセンティブとは異なる制限になっている。
新しい設計案
↑のような問題を抱える中、新しいmempoolの設計案は、mempool上でトランザクションの全体的な順序を付けて保持しようというもの。
ただ、単純にmempool内のすべてのトランザクション組み合わせの候補を検索し、最も高い手数料率のものを選択するというのを繰り返すという方法だと、指数関数的な実行時間を必要とするため機能しない。
クラスターの構築
- mempool内の全トランザクションでグラフを形成する。
- エッジで接続されたトランザクションのセットをクラスターとする。
- クラスターのセットが構成されると、各トランザクションは互いに素なクラスターに分割され、各トランザクションは必ず1つのクラスター内に存在しているという状態になる。※ どのトランザクションともエッジがないトランザクションは、それ単体が1つのクラスターになる。
リニアライゼーション
トランザクションのクラスターが構成されると次にそのクラスターに対して順序付けを行う。この順序付けのことをリニアライゼーションと呼んでいる。リニアライゼーションは抽象化されいて、具体的なソートアルゴリズムが定義されているわけではない。順序付けができればいいので、既存の祖先手数料率ベースのアルゴリズムでもよければ、トランザクションのすべてのサブセットの組み合わせから収益性が最も良いセットを選択するような最適化アルゴリズムでも良い。
クラスターの制限
クラスターを構成して順序付けをしても、クラスター内に新しいトランザクションを追加すると、クラスター内のトランザクションの順序もそれまでとは全く異なる順序に変わる可能性があるため再度順序付けを行う必要がある。ただ、巨大なクラスターが登場すると、その順序付けの実行も現実的ではなくなるので、クラスターに対してサイズ制限を設ける。
サイズ制限により実行時間にリミットを設けることで、常に個々のクラスターの順序を維持できるようにする。サイズによって指数時間を必要としていた最適な組み合わせの順序付けも実現可能なレベルの時間になる可能性が出てくる。
チャンク
一番ヘビーなリニアライゼーションが終わったら、マイニングや退去の対象となるトランザクションのグループを作るためにリニアライゼーションされたトランザクションリストのチャンク化を行う(リニアライゼーションはクラスター内の順序付けなので、mempool内の全クラスター内の比較はこの時点ではまだできてない)。
たとえば、次のようなトランザクショングラフを持つクラスターについて

リニアライゼーションした結果のトランザクションリストが以下の場合(カッコ内は手数料とサイズ)

まず、リストの先頭から累積手数料率を計算し最も高いサブセットを見つける。↑の場合、

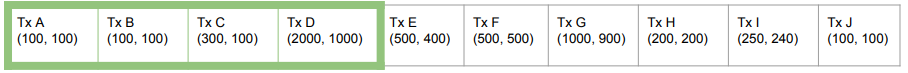
Tx A〜Tx Dまでが最初のチャンクになる。続いて、残ったリストの先頭(↑ではE)からこれを繰り返す。すると、
| チャンク | 累積手数料率 |
|---|---|
| Tx A〜Tx D | 1.92 |
| Tx E | 1.25 |
| Tx F〜Tx G | 1.07 |
| Tx H〜Tx I | 1.02 |
| Tx J | 1.01 |
というチャンクに分割される(※ 手数料率が同じ場合は、チャンクは小さい方が良いのでマージしない)。
結果、手数料率が単調減少するチャンクのリストが構成される。
mempoolの操作
mempoolのクラスター化、リニアライゼーション、チャンク化がすべて終わったら、それ利用してmempoolの各操作を実装するアルゴリズムを作ることができる。
マイニング
マイニング対象のトランザクションセットの構成は、貪欲法を使って実装できる。各クラスターの先頭のチャンク(=最も累積手数料率の高いチャンク)をピックアップ/ソートし、一番手数料率の高いトランザクションパッケージを候補ブロックに追加していく。追加したチャンクのクラスターにまだチャンクが残っていればそれをピックアップする。これをブロックスペースが埋まるまで繰り返す。
ただ、ブロックスペースを埋める終盤になってくると、残りのサイズに対してチャンクがフィットしない可能性が出てくるので、それは別途対応が必要。
退去
mempoolが溢れる場合は、↑のマイニングと逆の処理をして退去対象のトランザクションパッケージをピックアップする。各クラスターから一番最後のチャンク(最も累積手数料率が低いチャンク)をピックアップ/ソートし、一番手数料率の低いパッケージをmempoolから削除する。削除したチャンクのクラスターにまだ他のチャンクが残っていたらピックアップする。これをmempoolが十分なサイズになるまで繰り返す。
この結果、マイニングアルゴリズムで最後に選択されるであろうトランザクションパッケージから順に退去させられるようになる。
RBF
RBFについては、置換トランザクションをクラスターに適用した場合のチャンクの手数料率と、置換によって削除されるトランザクションのチャンクの手数料率を比較するようにする。こうすることでマイニングのインセンティブと適合する形でRBFの判断ができるようになる(結果、BIP-125の未承認の親Tx追加のNGルールはなくなる)。
ただし、DoS対策として以下のルールが適用される:
- 置換トランザクションは、削除されるすべてのトランザクションによって支払われた手数料の合計よりも多くの総手数料を支払う必要がある。
- 置換トランザクションは、100?を超える既存のトランザクションを削除してはならない。
2つめのルールは、単一のトランザクションの処理中にmempool内の大量の再クラスタリング/リニアライゼーションが発生しないようにするためのもの。
今後
以上が新しいmempoolの設定の提案で、このロジックのドラフト実装は既にできおり、現在はこれまでのトランザクション履歴に対して、このロジックの影響を分析中とのこと。
実際に適用されるにしても、まだ先の話になりそう。あと実際適用するとなったら、適用ノードと非適用ノードでmempoolの動作が変わるので、混在期間中のトランザクションのリレー状況がどうなるのかちょっと気になる。