以前、Googleが公開したP-256のようなNTTに適していないNISTの曲線でも、LigeroとSumcheckを組み合わせてmdoc(mDL)の選択的開示をゼロ知識証明可能にする発表について書いた↓
techmedia-think.hatenablog.com
このスキームはGoogleがgoogle/longfellow-zk というC++ライブラリとして実装・公開している。今回はそのRubyバインディングをlongfellowというgemとして実装したので、実際にmdocから「18歳以上である」というプルーフを生成して検証するところまでを動かしてみた。
longfellow-zkのRubyバインディング
longfellow-zkはC++のライブラリで、mdoc/mDLの匿名認証のためにC ABI(run_mdoc_prover / run_mdoc_verifier / generate_circuit など)を公開している。今回のgemは、このC ABIをRuby-FFI 経由で呼び出すことで、Rubyからプルーフの生成・検証をできるようにしたもの。
バインディングしたlongfellow-zkは現時点の最新タグv0.9ベースで、公開しているZKシステムは longfellow-libzk-v1。mdoc/mDLのC ABI(circuits/mdoc/mdoc_zk.h)のみをラップしている(JWT/W3C VCについてはまだ開発・テスト中のようでCのABIが公開されていない)。
ネイティブライブラリはgemのインストール時にsubmoduleで同梱しているソースからビルドされる。ビルドにはC++17コンパイラ、CMake、OpenSSL(libcrypto)、zstdが必要↓
$ sudo apt-get install build-essential cmake clang libssl-dev libzstd-dev
$ git clone https://github.com/azuchi/longfellow.git
$ cd longfellow
$ git submodule update --init --recursive
$ bundle install
$ bundle exec rake compile
仕組みの全体像
実際にコードを見る前に、前回の論文の内容とAPIの対応を整理しておく。証明者と検証者がやり取りする流れはこうなる↓
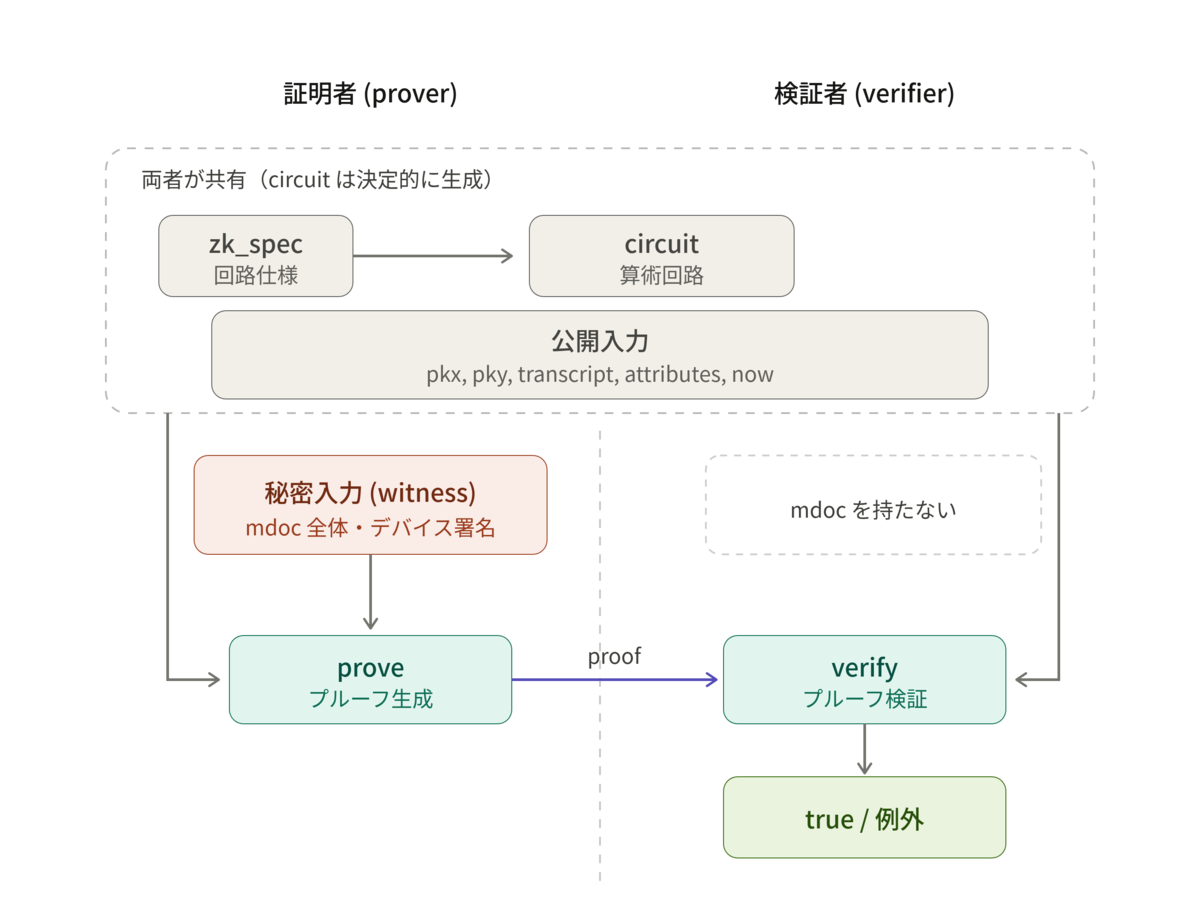
zk_spec:どの回路フォーマット(開示する属性数やバージョン)を使うかを表す仕様。ライブラリにハードコードされている。circuit:zk_spec から決定的に生成される算術回路のバイト列。論文でいう「ECDSA署名検証回路 + SHA-256回路 + CBORパース回路」を組み合わせたもの。決定的なのでキャッシュして証明者・検証者で共有できる。- 公開入力: 発行者の公開鍵
pkx/pky(x, y座標)、セッショントランスクリプト transcript、開示する属性 attributes、現在時刻 now。検証者も知っている値。
- 秘密入力(witness) :mdoc全体とデバイス署名。証明者だけが持っていて、
prove に渡すが verify には渡さない。
verify の引数には mdoc本体が出てこないのがポイント。証明者はmdocを開示せずに「age_over_18 = true を含む有効なmdocを持っている」ことだけを証明する。これが前回書いたリンク不能性を実現するための重要な要素。
ZkSpec を選ぶ
まずどの回路仕様を使うかを選ぶ。zk_spec はライブラリにハードコードされていて、Longfellow.zk_specs で一覧できる↓
require "longfellow"
Longfellow.zk_specs.each_with_index do |s, i|
printf("[%2d] system=%s version=%d attrs=%d hash=%s...\n",
i, s.system, s.version, s.num_attributes, s.circuit_hash[0, 16])
end
[ 0] system=longfellow-libzk-v1 version=7 attrs=1 hash=8d079211715200ff...
[ 1] system=longfellow-libzk-v1 version=7 attrs=2 hash=6a5810683e62b6d7...
[ 2] system=longfellow-libzk-v1 version=7 attrs=3 hash=8ee4849ae1293ae6...
[ 3] system=longfellow-libzk-v1 version=7 attrs=4 hash=5aebdaaafe17296a...
[ 4] system=longfellow-libzk-v1 version=6 attrs=1 hash=137e5a75ce72735a...
...
[11] system=longfellow-libzk-v1 version=5 attrs=4 hash=fa5fadfb2a916d3b...
v0.9 には全部で12個の仕様が入っていて、バージョン(7/6/5)*1× 一度に開示できる属性数(1〜4)の組み合わせになっている。circuit_hash はその回路の識別子(後述の circuit_id と一致する)。
今回は「18歳以上」を1つだけ開示したいので、属性数1の最新版 kZkSpecs[0] を使う↓
spec = Longfellow.zk_specs.first
システム名と回路ハッシュから引くこともできる↓
spec = Longfellow.find_zk_spec("longfellow-libzk-v1",
"8d079211715200ff06c5109639245502bfe94aa869908d31176aae4016182121")
回路を生成する
選んだ zk_spec から算術回路を生成する。これは決定的な処理で、証明者・検証者の双方が同じ結果を得る。一度生成すればキャッシュして使い回せる↓
circuit = Longfellow.generate_circuit(spec)
circuit.bytesize
Longfellow.circuit_id(circuit, spec).unpack1("H*")
spec.circuit_hash
circuit_id が spec.circuit_hash と一致することで、「自分が手元で生成した回路が、相手が想定している回路と同一である」ことを確認できる。改ざんされた回路を掴まされていないかのチェックになる。
自分の環境では generate_circuit に約9.5秒かかった。生成された回路は約299KB(299,152バイト)。これは内部的には2つの回路(後述する署名検証回路 sig 約5.8MBと、SHA-256回路 hash 約93MB)を1つのバッファに連結した約99MBを、まとめてzstd*2で圧縮した結果になっている。つまり circuit.bytesize の299,152バイトには 両方の回路が含まれている(circuit_id がこのバンドルを2つの回路に分けてパースするのもそのため)。回路生成はそれなりに重いので、実運用では生成済みの回路を配布・キャッシュする想定になると思われる。
開示する属性を指定する
開示する属性は Longfellow::Attribute で表す。前回触れたように、mdocの属性はCBORでエンコードされている。age_over_18 = true のCBOR表現は 0xf5(CBORの true)の1バイト↓
attribute = Longfellow::Attribute.new(
namespace_id: "org.iso.18013.5.1",
id: "age_over_18",
cbor_value: "\xF5".b
)
namespace_id / id / cbor_value の3つは、前回の記事で出てきたmdocのハッシュ元データの elementIdentifier と elementValue に対応する。証明者は「この名前空間のこの属性が、この値(のCBORバイト列)を持つ」ことを回路の中で検証させる。ハッシュ値の元になっているランダムなナンスはmdoc側に入っていて、回路内で参照される。
ハッシュ・文字列の入る固定長バッファに合わせて namespace_id <= 64、id <= 32、cbor_value <= 64 バイトの上限がある。Hashで渡すこともできる↓
attributes: [{ namespace_id: "org.iso.18013.5.1", id: "age_over_18", cbor_value: "\xF5".b }]
プルーフを生成する(証明者側)
公開入力と秘密入力(mdoc)を揃えて prove を呼ぶ。今回はlongfellow-zkのテストベクター(後述)を使う↓
proof = Longfellow.prove(
circuit: circuit,
mdoc: mdoc_bytes,
public_key_x: issuer_pkx,
public_key_y: issuer_pky,
transcript: session_transcript,
attributes: [attribute],
now: "2024-01-30T09:00:00Z",
zk_spec: spec
)
proof.bytesize
生成されたプルーフは約361KB(360,756バイト)。手元では約0.65秒で生成できた。
prove が失敗すると Longfellow::ProverError が送出される。たとえば指定した属性がmdocに含まれていない、now が有効期限の範囲外、mdocが壊れている、といったケース。エラーは#symbol とC ABIの戻り値 #code を持つ↓
begin
Longfellow.prove(...)
rescue Longfellow::ProverError => e
e.symbol
e.code
end
プルーフを検証する(検証者側)
検証者側は mdocを持たずに プルーフを検証する(引数に mdoc は無い)↓
ok = Longfellow.verify(
circuit: circuit,
public_key_x: issuer_pkx,
public_key_y: issuer_pky,
transcript: session_transcript,
attributes: [attribute],
now: "2024-01-30T09:00:00Z",
proof: proof,
doc_type: Longfellow::DEFAULT_DOC_TYPE,
zk_spec: spec
)
検証は成功すると true を返す。手元では約0.31秒だった。失敗時は Longfellow::VerifierError を送出する。試しにプルーフの最後の1バイトを反転させてみると、ちゃんと検証に失敗する↓
tampered = proof.dup
tampered[-1] = (tampered[-1].ord ^ 0xFF).chr
Longfellow.verify(circuit:, ..., proof: tampered, ...)
内部では何が起きているか
ネイティブライブラリは実行時に内部のログをstderrに吐くので、プルーフ生成中のログを見ると前回の論文の内容との対応が確認できる。prove 実行時の主要なログを抜粋すると↓
Compiled circuit: sig
depth: 22 wires: 223876 in: 3739 out:90 ...
sig bytes: 5834530 id:2845210a...
Compiled circuit: hash
depth: 18 wires: 3452075 in: 85118 out:2 ...
hash bytes:98932952 id:58248d20... # ← sig+hash の累積サイズ
zstd from 98932952 --> 299152 # ← 両回路まとめて圧縮
ZK Commit start
ZK Commitment done
...
ZK sumcheck done
ZK hash proof done
...
ZK sumcheck done
ZK signature proof done
com:32, sc:18656, com_proof:142472 ...: 161160b
com:32, sc:36032, com_proof:163436 ...: 199500b
proof_len: 360756
ここから読み取れることは、
- 回路が
sig(署名検証回路) と hash(SHA-256回路) の2つに分かれてコンパイルされている。これは前回書いた「ECDSA署名検証回路」と「SHA-256回路」に対応する。ここで「3つ目のCBORパース回路はどこに行った?」と思うけど、CBORパースは独立した回路ではなく hash 回路に吸収されている。hash 回路の実体(mdoc_hash.h)はCBORデコーダ(cbor_parser)を取り込んでいて、「MSOが正しいCBOR構造になっていること」と「その中のダイジェストがSHA-256と一致すること」を一体で検証する。だから hash 回路は純粋なSHA-256ではなく「SHA-256 + CBORパース」で、これが下で見るように巨大になる一因でもある
hash 回路がwires約345万・約93MB(sigの5.8MBに対して約16倍)と圧倒的に大きい。SHA-256のラウンド関数を回路化するとこれだけ巨大になる、というのが前回の「1ブロックで約13万要素」という話の実例になっている。なお hash bytes:98932952(≈99MB)は sig と hash を連結した累積サイズで、zstd from 98932952 --> 299152 はこの両回路をまとめて約299KBに圧縮したログ。circuit.bytesize の299,152バイトがこのバンドルにあたる。ZK Commit(Ligeroのコミットメント)→ ZK sumcheck(Sumcheckプロトコル)→ proof という流れになっていて、これも前回の「実行トレースをLigeroでコミットし、回路の検証をSumcheckで行う」という構成そのもの。- 最終的なプルーフ(360,756バイト)は
[96バイトのMAC][hashサブプルーフ][sigサブプルーフ] という並びになっている。hashサブプルーフ(161,160バイト)+ sigサブプルーフ(199,500バイト)= 360,660バイトで、proof_lenとの差96バイトが先頭のMAC。この96バイトが、論文の「ECDSAとSHA-256の回路は異なる体で動作するため、各回路の入力整合性をMACで検証する」で言っていた、2つの回路を繋ぐMACそのもの。2回路が共有する入力は 3つ(署名対象 e とデバイス公開鍵の dpkx / dpky)で、いずれも P-256 の体 Fp256 の要素=256ビット。一方 MAC は hash 回路側の体 で計算するため、128ビットの要素1個では256ビットの値を認証しきれず、1入力あたり要素を2個使う(コードにも
で計算するため、128ビットの要素1個では256ビットの値を認証しきれず、1入力あたり要素を2個使う(コードにも f_128::kBits * 2 >= Fp256Base::kBits のチェックがある)。結果、3入力 × 2要素 × 16バイト = 96バイト。
- おもしろいのが、
hash 回路は93MB・sig 回路は5.8MBと規模が約16倍違うのに、サブプルーフのサイズは hash 161KB < sig 199KB と逆転している点。これは2段階で効いている。まず Ligero+Sumcheck のプルーフサイズは回路のワイヤ数に対して劣線形なので、16倍というワイヤ数の差はプルーフの段階で大きく縮む。そのうえで効いてくるのが体の要素サイズで、sig 回路はP-256の体 Fp256(要素256ビット = 32バイト)、hash 回路は標数2の体(要素128ビット = 16バイト)で動くため、要素1個あたり sig 側が2倍大きい。縮んだうえで要素サイズ差が乗ることで、ワイヤの多い hash より sig のプルーフが上回る。実際ログから、Sumcheck部分は sc が sig:36032 / hash:18656 ≈ 1.93倍 ≒ 要素サイズ比2倍、コミットメント開示も com_proof が 163436/142472 ≈ 1.15倍で、ワイヤ数で勝るはずの hash 側を sig 側が要素サイズで逆転しているのが数字から分かる。
論文を読んだだけだと抽象的だった「回路を層に分割してSumcheckで検証する」「2つの回路をMACで繋ぐ」あたりが、実際に動かしてログを見ると具体的なサイズ感を持って腑に落ちる。
テストベクターについて
上の例で使ったmdoc・トランスクリプト・公開鍵は、同梱したlongfellow-zkのテストベクター(lib/circuits/mdoc/mdoc_examples.h)から抽出したもの。gemのリポジトリでは spec/fixtures/mdoc_example_0.txt として持っていて、age_over_18 = true を含むGoogleのテスト用mDLになっている。
実際のプルーフ生成・検証のラウンドトリップは :slow タグ付きのintegration specとして用意してあるので、手元で動かす場合は↓
$ bundle exec rake compile # ネイティブライブラリのビルド
$ bundle exec rspec --tag slow # 実際の prove -> verify ラウンドトリップ
論文を読むだけだと掴みにくかった部分も、実装を叩いて動かすとサイズ感や処理の流れが具体的になってよかった。JWT/W3C VCも早く使えるようになるといいな。
)
を使ってeに対してPQC署名
を生成する
を計算し、
を署名とする。
でRを復元し、
とeに対して検証する
を係数として使用する