BitVMXは、少し前にRootstockLabsが発表したBitVMベースの新しい設計↓
https://bitvmx.org/files/bitvmx-whitepaper.pdf
BitVMファミリー
最初に発表されたBitVMは、任意の計算処理について回路を構成し、それをTaprootのスクリプトツリーとしてエンコードし、その計算結果の検証をBitcoinのブロックチェーン上で楽観的(Fraud Proofベースのアプローチ)に行えるようにしようというものだった↓
Bitcoin上で任意の計算の検証を可能にするBitVM - Develop with pleasure!
これはBitVM 0と呼ばれている。
ただ、論理ゲートを直接操作するようなことは現実的なアプローチではないとして、計算を仮想CPUの命令シーケンスとして表現するようにした改良版がBitVM 1と呼ばれている。
その後、任意の計算の検証の部分をSNARK検証器の検証にし、マルチパーティ対応したものがBitVM 2↓
BitVM 2 - Develop with pleasure!
今回発表されたBitVMXは、仮想CPUを用いるという点でBitVM 1と似ているけど、計算のトレースやプログラム、メモリの保存にマークルツリーを使用しないアプローチを取ることでメモリ効率や計算コストを削減する新しい設計を採用している。
BitVMXのアーキテクチャ
仮想CPU
BitVMXはRISC-VやMIPSなどの一般的なCPUアーキテクチャをシミュレートできる仮想CPUを定義している。BitVMXで検証可能な任意のプログラムは、この仮想CPUで実行される命令のセット。CPUで実行される命令のレイアウトは↓

メモリから2つの値(read 1, 2)と、1つのopcode(readPC)を読み取り、演算を実行し、結果をメモリに書き込む(write)。さらに、プログラムカウンタ(writePC)を変更して次の命令アドレスを指定する。各メモリ(read 1, 2)のlastStepフィールドには、読み取った値が最後に書き込まれたプログラムのステップ番号が格納される。
実行トレースのハッシュチェーン
仮想CPU上の各命令の実行は実行トレースとして記録される。i番目のステップのトレース情報は、上記のデータを連結したもの↓
この内、出力フィールドのみのトレースが↓
そして、実行された各命令の実行トレースハッシュチェーンを構成することで、プログラムの実行にともなう状態遷移を表現することができる。
Hはハッシュ関数で、現在の実行ステップ(i)のトレースを前の実行ステップ(i - 1)のハッシュに追加し、その結果をハッシュすることでハッシュチェーンが構成される。ハッシュチェーンはtraceのみで構成され、fulltraceの方はチャレンジ&レスポンスで証明者がステップ情報を開示する際に使われるみたい。
BitVMXの参加者は、それぞれプログラムをローカルで実行し、その実行トレースのハッシュチェーンを計算する。参加者間で実行トレースに違いがあるとこのハッシュチェーンは分岐する。
CPUの初期化
CPUを初期化するにあたって、各命令をfulltraceのマイナス位置に書き込むようになっている。実行する命令がm個ある場合、〜
に各命令の書き込み操作をfulltraceで定義する。ハッシュチェーンの初期位置のstepHashを
として、i = -m〜i=-1までの各命令を定義したstepHashを事前に計算する。このハッシュチェーンの結果の
がCPUの初期状態となる。
実際に書き込まれる命令は、(後述する)実行結果の間違いの検証時にオンチェーンで実際に実行するとあるので、Bitcoinで使用可能なopcodeだと思われる。ただ、Bitcoinのopcodeは算術演算は32-bitに限定されていたりと、現状のopcodeのみで十分なのかは怪しい。
各命令は特定のメモリアドレスにあり、プログラムを格納するメモリアドレスの範囲は読み取り専用で、プログラム入力用の読み取り専用メモリアドレスの範囲を定義する。残りのメモリアドレスは0で初期化され、lastStepは特殊な値INITIALで初期化されるということだけど、このあたりのメモリの仕様は↑のstepHashとどう関係するのかあたりがまだよく分かってない。
チャレンジ&レスポンス
計算結果に異議がある場合は、他のBitVMプロトコルと同じようにチャレンジ&レスポンスによる検証プロトコルを実行することになる。
- チャレンジ&レスポンスは、オペレーター(レスポンダー)がプログラムの入力値と最終結果のstepHash値を提供することで、トリガーされる。
- この計算結果に賛同できない場合、検証者(チャレンジャー)はCPUの初期状態から計算が正しく実行されていない最初の計算ステップを特定する。
- ステップを特定したら、ステップ内のどこ(メモリからのデータの読み取り、PCの読み取り、opcodeのフェッチ、計算の実行、結果の書き込みなど)に問題があるのかを特定する。
まず、2の計算ステップの誤りを特定する方法について。
- 検証者は、オペレーターに対して特定のステップの情報とそれに対する署名を要求する。
- オペレーターは要求されたステップのfulltrace情報、stepHashとそれに対する署名を検証者に返す。
- 検証者は、オペレーターが返したstepHashが正しい計算結果のstepHashかどうかチェックする。正しいstepHashと間違ったstepHashが連続して続くポイント(誤りのポイント)を発見するまでこの探索を繰り返す*1。
ステップi - 1と誤ったステップiのデータがあれば、をオンチェーンで証明できる。
ステップが特定できたら、続いてステップ内のどこが間違っているのかを特定をする(↑の3)。
メモリの読み取りが間違っている場合
各トレースデータには、読み取ったメモリのデータが最後に書き込まれたステップ番号が記載されているため、検証者はそのステップ情報をオペレーターに要求する。オペレーターから返ってきたデータについて、
- 対象のステップのstepHashが正しい場合
書き込まれているメモリの値と読み取ったメモリの値が異なるため、オペレーターが誤ったメモリの値を提供したことが証明できる。 - 対象のステップのstepHashが誤っている場合
検証者は新しい探索プロセスをトリガーする。↑の探索プロセスと似ているけど、今回は誤ったstepHashの後に正しいstepHashが続く↑とは逆のパターン。
プログラムカウンタが間違っている場合
ステップiのPCが間違っている場合は、と
を提供することで、検証者は以下をオンチェーンで検証することで不正を証明することができる。
最初の検証で検証者が正しいと
を提供していることを保証した上で、2つめの検証で、ステップ
i - 1実行後の次のPCと提供されたステップiのPCと異なっていることを検証している。
opcodeが間違っている場合
↑のようにCPUの初期化時に各命令はマイナス位置のfulltraceに書き込まれている。オペレーターから提供されたステップiのopcodeが間違っている場合、検証者はそのopcodeのが指すマイナス位置のステップ情報をオペレーターに要求する。ここで返ってくるopcodeと元々の
が異なっていることをオンチェーンで証明する。
実行結果が間違っている場合
ステップiの実行結果(または
)が間違っている場合は、命令をオンチェーンで実行して、書き込み結果を検証することで証明する。
以上がエラー箇所別の検証内容。オペレーターが提供する各データにはオペレーターのワンタイム署名*2が付与されるので、その署名を用いて確かにオペレーターが提供したデータで、その内容に誤りがあることを、↑の各方法で証明するみたい。
メッセージリンクスキーム
上記のチャレンジ&レスポンスは、Bitcoinのトランザクションチェーンで実行される。その際、検証したいステップのデータを共有する必要があるけど、Bitcoinにはトランザクション間で状態データを転送するための標準的な仕組みはないので、チャレンジ&レスポンスにおける状態データを共有するフレームワークとしてメッセージリンクスキームという構成を提案してるみたい。事前署名をするトランザクションチェーンという位置づけは他のBitVMファミリーと一緒。
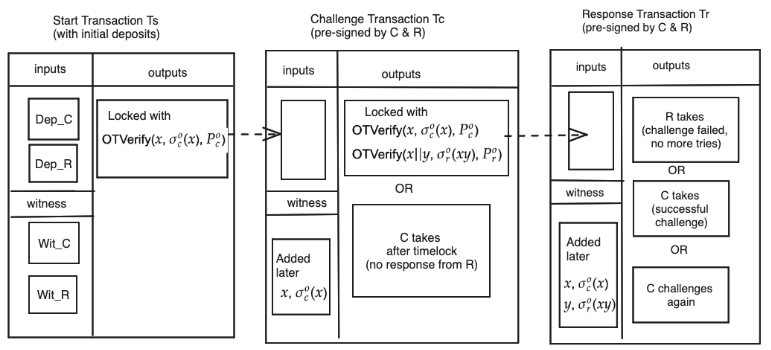
概要はざっくり分かったけど、ロードマップでは、
とあるので、実際にリリースされるともう少し解像度上がりそう。