Ethereumのステートを管理する上で重要な構成要素の1つがMerkle Patricia Trie。ビットコイナーならマークルツリーはお馴染みだが、Merkle Patricia Trieはマークルツリーとはだいぶ勝手が違うデータ構造なので、どんな仕組みで構築されて、特定のアイテムがそれに含まれていることをどう探索、検証しているのか、またそのボトルネックについてまとめておく。
ステートの種類
Ethereumのブロックヘッダーには、以下の3つのステートツリーのルートハッシュが記録されてる。
- ステートルート:
俗にワールドステートと呼ばれる、各アカウントのステートで構成されるツリーのルートハッシュ。 - トランザクションルート:
ブロックに含まれるトランザクションで構成されるツリーのルートハッシュ。 - レシートルート:
トランザクションレシートで構成されるツリーのルートハッシュ。
ステートルートのリーフノードのデータには、ストレージルートが含まれている。つまり各アカウントはそれぞれストレージのステートツリーを持っており、そのルートハッシュが↑のステートツリーのリーフのデータとして記録されている。
結果、Ethereumのフルノードは4つのMerkle Patricia Trieを管理している。各Merkle Patricia Trieのkey-value値は以下のとおり:
| Trie | key | value |
|---|---|---|
| ステートツリー | アドレスのKeccak-256ハッシュ | 残高、nonce、ストレージルート、コードハッシュで構成されるステート |
| トランザクションツリー | トランザクションのブロック内のインデックス | トランザクションデータ |
| レシートツリー | トランザクションのブロック内のインデックス | レシートデータ |
| ストレージツリー | 各コントラクトの変数のハッシュ値*1 | ストレージの値 |
Merkle Patricia Trieの構成要素
マークルツリーは、リーフノードと、2つの子ノードのハッシュ値を連結して自身のハッシュ値を計算する内部ノードの2種類のノードのみでシンプルだが、Merkle Patricia Trieには、以下の4種類のノードが存在し、それぞれ保持するデータが異なる。またアイテムはkey-valueのマッピングで構成される。
- ブランクノード:
空のTrieで、ツリーの初期状態。 - ブランチノード:
ツリーの内部ノード兼リーフノード的な位置づけのノードで、17個のリストを持つ。16個のアイテムは子ノードの32バイトのハッシュ値を保持している(つまりブランチノードは最大16個の子ノードを持つ)。17個めの最後のアイテムは、keyの最後がこのブランチノードで終わる場合のvalue値が入る。 - リーフノード:
ツリーの末端のノードで、パス(ニブル)とvalue値を持つ。このvalueは実際に保存するステートの値。 - エクテンションノード:
ツリーの内部ノードで、パス(ニブル)とvalue値を持つ。リーフノードと似ているけど、valueはステートの値ではなく、他のノードのハッシュ値になっている。LevelDBに対して、このハッシュ値でルックアップすると、子ノードの情報を入手できる。
アイテムをツリー内のどこに配置するかは、アイテムのkey-valueのkeyによって決まる。つまりkeyはツリー内のアイテムが存在するノードのパスであると言える。そして、リーフノードとエクステンションノード内のパスは、そのパスのデータの一部で、ニブルの配列。
アイテムの登録に伴い、これらのノードがどう解釈され、どうアイテムが探索、追加されるのか?具体的にみていこう。
アイテムの探索
ツリー内のあるアイテムを探索する場合、アイテムのkeyを指定してルートノードから探索する。
まず、自明なことだけど、ツリー内のアイテム数が1でそのアイテムしかない場合、ルートノードはリーフノードでそのアイテム自身だ。
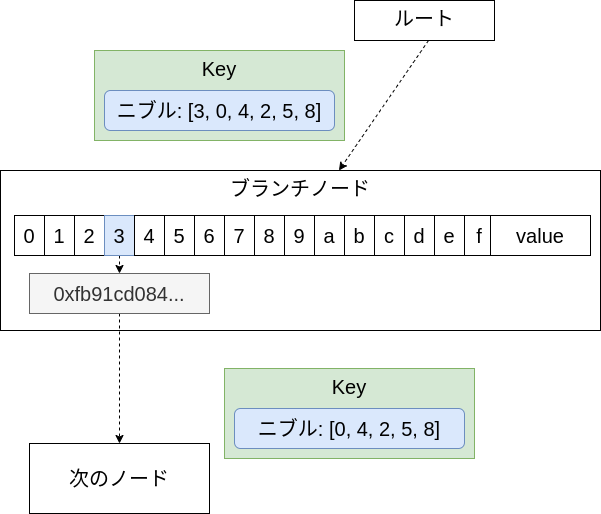
それ以外に、ツリーに複数のアイテムが登録されている場合、ルートノードは、ブランチノードかエクステンションノードのいずれかになる。この場合、まずkeyをニブルに変換する。変換した値を3, 0, 4, 2, 5, 8としよう(Ethereumの場合、keyはKeccak-256ハッシュなので、実際は64個)。
- ブランチノードの場合:
ニブルの最初の要素が3なので、ブランチノードの0〜15個の16個のリストの4つめのアイテムを取得する。これは子ノードのハッシュ値なので、LevelDBにこのハッシュ値の子ノードを問い合わせる。この時、keyのニブル3は消化したので、その子ノードの探索は0, 4, 2, 5, 8のニブルで継続する。
- エクテンションノードの場合:
エクステンションノードのニブルと、keyのニブルの合致する部分をチェックし、エクステンションノードのvalue値を取得する。これは子ノードのハッシュ値なので、LevelDBにこのハッシュ値の子ノードを問い合わせる。この時、エクステンションノードのニブルが3, 0, 4だった場合、それらは消化したので、子ノードの探索は残りのニブル2, 5, 8で行う。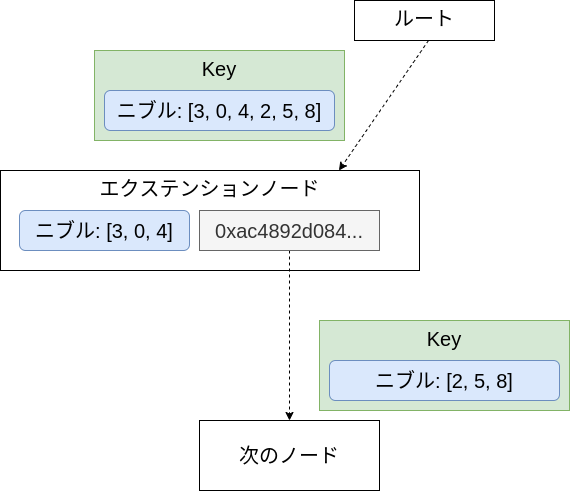
↑の探索を行うと次のノードは、ブランチノードか、エクステンションノードか、リーフノードのいずれかになる。リーフノードの場合、そのキーの値はそのノードから取得できる。ブランチノードかエクステンションノードの場合は、↑と同じ処理を続けて、最終的にリーフノードまで探索を続ける。
内部ノードの種類がブランチノードだけでなくエクステンションノードが存在する理由は、リーフノードの探索をショートカットするためだ。ブランチノードだけだと、keyが32バイトなので、ブランチノードはそのニブルを1つずつしか合致できないので、どのアイテムも64階層めにリーフノードが存在することになり、探索コストが大きくなってしまう。そこで、keyが共通の値をもつ部分をエクステンションノードやリーフノードのニブルとして保持することで、探索するノード数を減らしている。
アイテムの登録
マークルツリーの場合、登録するアイテムのハッシュをリーフノードとして、そこを起点に親(内部)ノードを計算し、最終的にルートノードのルートハッシュを計算するが、Merkle Patricia Trieの場合、ルートノード(最初はブランクノード)を起点にアイテムを登録してツリーを成長させていく。この時、↑の探索特性をサポートするため、探索した先のノードに応じて、以下のルールでツリーを構成していく。
- ノードがブランクノードだったら、リーフノードに置き換える。
- ノードがリーフノードだったら、それをエクステンションノードに変換し、その新しいブランチとしてリーフノードを追加する。
- エクステンションノードで停止したら、それよりパスが短い別のエクステンションノードに変換し、新しくブランチノードを作成しそれをエクステンションノードの子ノードとする。
ニブルのプレフィックス
↑では省略していたけど、リーフノードやエクステンションノードのパスであるニブルをエンコードする際は、ニブルの特性により先頭にプレフィックスがつくようになっている。それぞれ4bitのニブルはエンコードされる際はバイトになる。しかし、ニブルの個数は奇数になる場合もあり、その場合、バイトにするのに4bit分不足してしまう。例えばニブルが1だった場合、01とエンコードされてしまうと、ニブル0, 1と同値になり区別できなくなる。この問題を回避するためにニブルには、プレフィックスが付与される。
プレフィックスのルールは、
| hex文字 | ニブルの数 | ノードタイプ |
|---|---|---|
| 0 | 偶数 | エクステンション |
| 1 | 奇数 | エクステンション |
| 2 | 偶数 | リーフ |
| 3 | 奇数 | リーフ |
ニブルの数が偶数か奇数かに関係なくプレフィックスは付与され、1つ付与するだけだと逆に偶数のニブルが奇数になるので、偶数の場合は後ろに0がパディングされる。つまり、個数が偶数のニブルのプレフィックスは00か20。
なお、偶奇だけでなく、そのノードがエクステンションノードなのかリーフノードなのか(末端なのかどうか)を判断するためのフラグも加味されている。
データの保護
子ノードを持つ、ブランチノードとエクステンションノードはそれらの子ノードのハッシュ値を持っており、各ノードのハッシュ値はそのノードが保持するデータ(ブランチノードは最大16個の子ノードのハッシュ値とvalue値、エクステンションノードはニブルと単一の子ノードのハッシュ値、リーフノードはニブルとvalue値)のハッシュ値であるため、データが更新されるとそのハッシュ値が変わる。このあたりはマークルツリーと同様のツリー型のハッシュチェーンでデータを保護している。
Merkle Patricia Trieのボトルネック
Merkle Patricia Trieでステートを管理することで、ステートが更新された際その時点のステートにコミットするのに、全てのステートのハッシュを再計算する必要がなく、ツリー内の変更のあったノードのハッシュ値を再計算するだけで済むという恩恵を受けられる。これはステート更新時の計算コストを下げるというメリットがある反面、ステートの読み取りコストが増加する。単なるKVSであればあるキーに対応する値はO(1)でダイレクトにアクセスできるが、Merkle Patricia Trieでは目的のステートが保持されているノードを探索するコストが増える。
現状のmainnetで各アカウントのステートツリーがどのくらいの深さかは正確には分からないけど、2020年7月の記事では、2019年自体で深さ7が飽和していており、少なくとも7〜8の内部ノードにアクセスしているだろうと記載されている。つまりその回数分、LevelDBへのクエリが発行されていることになる。またLevelDB自体、データを階層化して管理する(最大7階層)という特性上、これによりディスクへのランダムアクセスがさらに増える。このあたりがEthereumのスケーリングにあたってディスクIOがボトルネックになっている要因。
これらを解消するため、マークルツリーのような二分木に移行しようという議論もされており、その仕組みについてはまた別の記事で。
*1:例えば、0番目の変数のkeyは、sha3(0000000000000000000000000000000000000000000000000000000000000000)