ノードが新しくブロックチェーンネットワークに参加した際、最初にチェーンの初期同期を開始するが、ブロックチェーンの成長と伴にこの初期同期のスピードというのがネックになる。先日リリースされたGeth v1.10.0では、Ethereumのブロックチェーンを同期する際の新しい同期方法がリリースされていたので見てみる↓
これまでの同期方法
Gethでは、これまでFull syncとFast syncと呼ばれる2つの同期方法がサポートされてきた。
Full sync
Full syncは初期からある同期方法で、Ethereumの各ブロックに含まれているトランザクションをすべて実行し、ローカルのステートツリーを更新する方法。最新のブロックまでステートツリーを更新し続けることで、ブロックチェーンを同期するシンプルな方法。
Ethereumのフルノードは、各アカウントが保持するetherの量や、コントラクトのコード、コントラクトが保持するストレージデータをすべて保持する必要があり、トランザクションを実行すると該当するこれらのステートデータが更新される。ただ、これらのデータをそのままブロックチェーンに記録することは(サイズ的に)できないので、そのステートへのコミットメントをブロックヘッダーに記録している。各データをリーフノードとし、全データで構成される巨大なマークルツリーのルートハッシュがこのコミットメントで、ブロックヘッダーにステートルートとしてセットされる。
ただ、Ethereumのブロックチェーンの累計トランザクション数は10億を超えている。そのため、初回起動したばかりのノードがジェネシスブロックからすべてのトランザクションを実行するというのは、ハードルの高い作業になった。結果、ノードのCPUリソースとディスクIOに負荷がかかり、性能の良いマシンで同期に1週間から10日かかるとされている。
Fast sync
チェーンの成長に伴いFull syncの同期時間が問題になったこともあり、Gethはv1.6からFast Syncという新しい同期方法を導入した(現在デフォルトの同期方法)。
Fast syncは、チェーンの先頭に近いピボットブロック*1を選択し、そのブロック時点のステートツリーをリモートピアから直接ダウンロードすることで、ローカルのステートツリーを構築するというアプローチを採った同期方法。ピボットブロック以降のブロックについてはFull syncと同様トランザクションを実行することでステートツリーを更新していく。
ダウンロードの仕組みを理解するには、Merkle Patricia Trieの構造を理解しておくのが良い↓
techmedia-think.hatenablog.com
ノードはブロックヘッダーの同期が終わると、ピボットブロックを選択する。そのブロックヘッダーから、そのブロック時点のステートツリーのルートハッシュが何かは知っている。なので、
- まずそのルートハッシュを指定して
GetNodeDataメッセージをリモートピアに送信して、ステートルートのノードデータを要求する。 - リモートピアは
NodeDataメッセージでルートノードのデータを返してくる。このノードはブランチノードで、さらに最大16個の子ノードをを持っている。 - ノードは続いて2の子ノードを取得するのに
GetNodeDataをリモートピアに送信する。
これを繰り返してツリーの探索を進め、ステートツリーのデータをすべてダウンロードすることで、ステートツリーを同期する。
この方法では、ジェネシスブロックからトランザクションをすべて実行する必要がなくなり、Full syncに比べて速くチェーンの同期が可能になった。しかし、これもステートの成長に伴い別のボトルネックが発生するようになる。
Fast syncのボトルネック
ステートの成長に伴い、GetNodeData/NodeDataを使ったステートをダウンロード処理自体がボトルネックになるようになってきた。Fasy syncでは↑のようにルートノードを起点にステートツリー内のすべてのノードをダウンロードすることになる。問題は現在のEthereumのステートツリーには約6億7500万個を超えるノードが存在するということだ。この結果、以下のボトルネックが報告されている。
- リモートピアにノードデータを要求するが、1リクエストあたり最大384個のノード要求をバッチ化できるが、それでもすべてのノードを要求するのにノードとリモートピア間で、最低でも175万回の通信の往復が発生する。10個のリモートピアと並列で実行したとしても、ネットワークのRTTを50msとすると、その合計は150分。
GetNodeData要求を受けたピアは、対象のノード情報を提供する必要があるが、その際ディスクアクセスが発生する*2。データ自体はGethの場合LevelDBに保存されているが、検索のキーはノードのハッシュ値になるので、基本的にランダムリードになる。結果ディスクリードは、1リクエスト384ノードの要求に対して、約2700回弱になり、SATA SSDで100,000IOPS出ると仮定しても、10個のピアで並列してすべてのノードを取得するのに108分のリード時間が発生。- ノードはすべてのノードを取得するために
GetNodeDataでメッセージでそのすべてのハッシュ値をアップロードしていることになる。ハッシュ値1つあたり32バイトなので、アップロードするハッシュ値の合計は、6億7500万×32バイト=約21GB。ダウンロードするノードデータの合計は、その2倍ちょっと。アップロードの速度を51Mbps、ダウンロードの速度を97Mbpsとすると、アップロードで56分、ダウンロードで63分それぞれかかる。
Full syncではCPUとディスクIOがボトルネックになっていたが、Fast syncではネットワークの帯域幅やレイテンシー、ディスクIOがボトルネックになっている。まぁそこにボトルネックが発生するほど、ステートが膨らんだ=利用されているということ。
Snap sync
↑のFast syncのボトルネックを軽減する新しい同期方法がステートのスナップショットを利用したSnap syncになる。これはSnap protocolとして定義されている。
Fast syncでステートツリーをルートノードを起点のツリーのノードをすべてダウンロードしているため、中間ノード(ブランチノードやエクステンションノード)もすべてダウンロードする必要があり、膨大な数のノードをダウンロードしなければならないが、Snap syncは、この中間ノードをダウンロードすることなくステートツリーを構築できるようにしようというものだ。
具体的には、各ノードはMerkle Patricia Trieとは別に、ブロックチェーンの特定のブロックにおけるViewとなるスナップショットを作成する。このスナップショットは、すべてのアカウントとそのストレージスロットのフラットなKey-Valueストアになる。このデータストアから、アカウントやストレージのデータを連続したデータチャンクとして入手できるようにすることで、そのステートデータからMerkle Patricia Trieを復元する。こうすることで、リモートピアからツリーの中間ノードをダウンロードすることなくそれらをローカルで計算することができ、最終的にルートノードまで計算される。余計な中間ノードをダウンロードしなくて済むので、その分のコストが不要になる。またこれらのデータを提供するピアにとっても、スナップショットからデータをリードする際にO(1)のダイレクトアクセスができるようになる。その結果、Fast syncと比べたSnap syncのコストは↓のように変化するとのこと。

ただ、Snap syncを利用するには前提としてリモートピアが、予めスナップショットを作成しておく必要がある。ただ、スナップショットはステートの参照にも利用可能で、eth_callの呼び出しは桁違いに高速になる。同期以外にも、そういうユースケースが求められるケースではスナップショットの恩恵が受けられそう。
当然ながら、次々と新しいブロックが来るのでスナップショットも随時更新していく必要がある。ただ、Ethereumにはファイナリティは無く再編成が発生する可能性があるので、ブロックが到着したら順次ステートを単純に上書きしていくということはできない。そこでGethのスナップショットは永続化レイヤーとインメモリの差分レイヤーで構成されている。基本的にステートの更新は永続化レイヤーに直接行わず、差分レイヤーに対して行う。十分な差分レイヤーが積み重なると、下のレイヤーから順に永続化レイヤーに書き込まれるという仕組み。なお、シャットダウン時にはメモリ上の差分レイヤーもジャーナルに保存されれ、起動時にそこからロードバックされる。と書くのは簡単だけど、実際の実装はもっと考慮すべきことが多く、結構ヘビーそう。
また、当然ながら同期中にもリモートピアのスナップショットは随時更新されることになるため、同期中に不整合なデータを受け取る可能性があるが、不整合は後で、Fast syncスタイルの同期方法を利用して修復する模様。
snap syncのトレードオフ
スナップショット作成するとハッピーになれそうな感じがする、ここにもトレードオフはある。
- スナップショットの作成に伴い、
- 最初だけだが、1日〜1週間かかる。
- Merkle Patricia Trieのデータの冗長コピーになるので、現状追加で20〜25GBのディスクスペースが必要になる。
- 再編成が発生した場合のリスクを吸収するのに、インメモリの差分レイヤーがあるが、永続化レイヤーに適用した変更を覆すチェーンの再編成が発生した場合、スナップショットを新規に作成しなおさなければならない。
というのが、Synap syncの仕組み。
フルノードが減少?
Ethereumのフルノードといえば、一時期Bitcoinより多かったが、最近みるとどうもフルノードの数が減少している。現在は6,500〜7,000台。
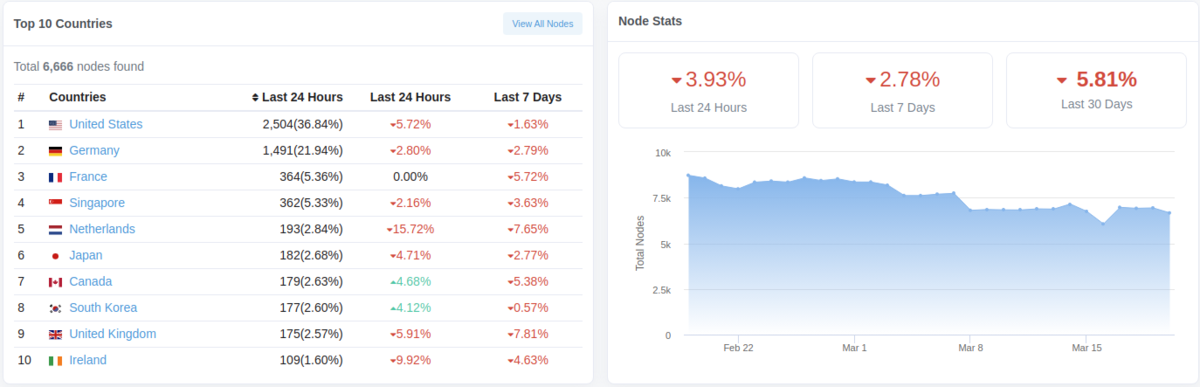
チェーンの成長と伴にEthereumのフルノードの運用コストも大きくなってるので、単純に運用者が減ってるのか?ただ、ノードが減少すると、↑のような同期をする際も既存のノードが負荷が上がるので、ノードの運用コストは重要なファクターになる。